- DNA -
DNAの立体構造をモデリングします.
メニューの意味は以下の通りです.
| ADE CYT GUA THY | 各残基を追加,挿入します. |
| ADE - THY CYT - GUA GUA - CYT THY - ADE | 各塩基対を追加,挿入します. |
| ACTION | ADD 追加,または挿入 REPLACE 残基の置換 |
| COURSE | 二次構造の表示上の進行方向を変更します. RIGHT, LEFT, UP, DOWNの4方向です. |
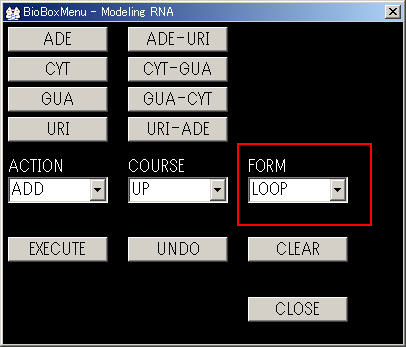
| FORM | STEM(ステム)かLOOP(ループ)かを変更します. |
| EXECUTE | 分子を作成します.二次構造が大きいほど作成時間が長くかかります. |
| UNDO | 一つ前の状態に戻します. |
| CLEAR | 二次構造を消去します.UNDOでは元に戻せないので注意してください. |
- RNA -
RNAの立体構造をモデリングします.
メニューの意味は以下の通りです.
| ADE CYT GUA URI | 各残基を追加,挿入します. |
| ADE - URI CYT - GUA GUA - CYT URI - ADE | 各塩基対を追加,挿入します. |
| ACTION | ADD 追加,または挿入 REPLACE 残基の置換 |
| COURSE | 二次構造の表示上の進行方向を変更します. RIGHT, LEFT, UP, DOWNの4方向です. |
| FORM | STEM(ステム)かLOOP(ループ)かを変更します. |
| EXECUTE | 分子を作成します.二次構造が大きいほど作成時間が長くかかります. |
| UNDO | 一つ前の状態に戻します. |
| CLEAR | 二次構造を消去します.UNDOでは元に戻せないので注意してください. |
- Peptide -
タンパク質の立体構造をモデリングします.
メニューの意味は以下の通りです.
| ALA 〜 VAL | 各アミノ酸を追加,挿入します. |
| FORM | タンパク質の形状を選択します. A-HELIX αヘリックス B-SHEET βシート RANDOM ランダム鎖(シミュレーション対象) SPECIFIC 任意角度 |
| PHI PSI OMEGA | FORMがSPECIFICの場合に任意の角度を設定します. +180.0° 〜 -180.0°の範囲で指定します. |
| EXECUTE | 分子を作成します.二次構造が大きいほど作成時間が長くかかります. |
| UNDO | 一つ前の状態に戻します. |
| CLEAR | 二次構造を消去します.UNDOでは元に戻せないので注意してください. |
- Extraction -
核酸やタンパク質の立体構造情報を抽出します.
ここで保存された情報をモデリングに用いることで,二次構造配列の比較から立体構造座標の変換までを自動化することができます.
Saveでは表示中の分子から立体構造情報を抽出し,保存します.
ファイルはMSS Extraction Structure(.MEX) という拡張子で保存されます.
分子が読み込まれていない状態では無視されます.
LoadではMEX形式のファイルを読み込みます.
ここで読み込まれた情報が次回のモデリングで有効となります.
Defaultを実行するとデフォルトで用意されている情報(default.mex)を次回のモデリングで使用します.
default.mexはBioBoxをインストールしたフォルダにあります.
また,default.mexには主にRNAの立体構造情報が記述されています.
- モデリング チュートリアル -
今回は以下のようなRNAの立体構造のモデリングを例に,作業の流れを説明します.
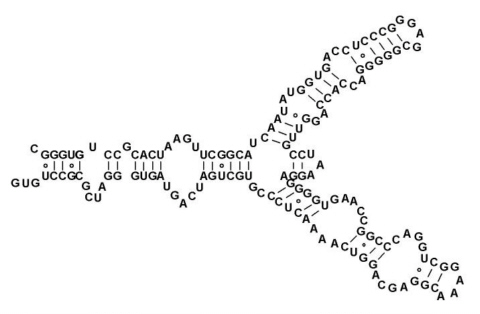
- STEP 0: 準備
- STEP 1: 配列の入力
- STEP 2: 置換
- STEP 3: 追加・挿入
- STEP 4: 分岐構造
- STEP 5: ループ作成
- STEP 6: 完成
- STEP 7: タンパク質のモデリング
STEP 0: 準備
BioBoxにおけるモデリングではまず二次構造(生体高分子の配列情報)を入力します.
二次構造の入力が終わったらEXECUTEを押すだけで立体構造が作成されます.
二次構造の配列情報や分子の大きさによっては作成に時間がかかりますが,非常にシンプルで簡単なモデリングを提供します.
まずは,作成したい二次構造を用意します.
Modeling メニューの RNA を選択します.
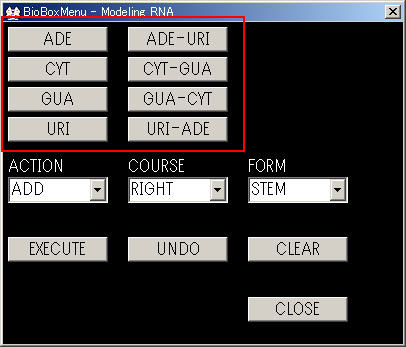
STEP 1: 配列の入力
基本的に配列の1残基目(RNAなら5'末端)から情報を入力していきます.
メニューウィンドウで追加したい残基をクリックすると二次構造表示ウィンドウに配列が表示されます.
二次構造ウィンドウの配列はマウスの右ボタンで動かすことができます.
CYT > GUA - CYT > GUA - CYT > GUA - CYT > URI - ADE > GUA - CYT
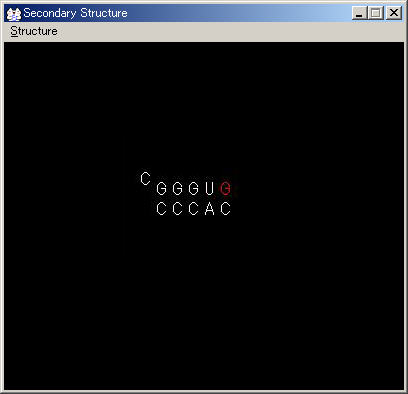
STEP 2: 置換
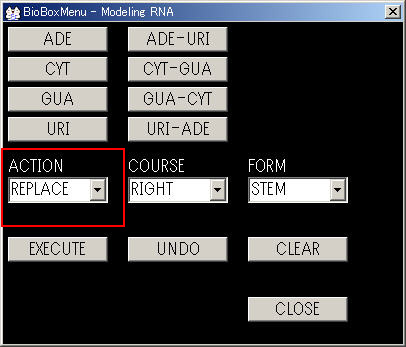
G-U塩基対のようにメニュー一覧にないものはACTIONをADDからREPLACEにしてCYTをURIに置換します.
二次構造表示ウィンドウ上で置換したい残基をマウスの左ボタンでクリックします.
メニューウィンドウから置換後の残基を選択します.

STEP 3: 追加・挿入
引き続きステム部分の配列を入力していきます.
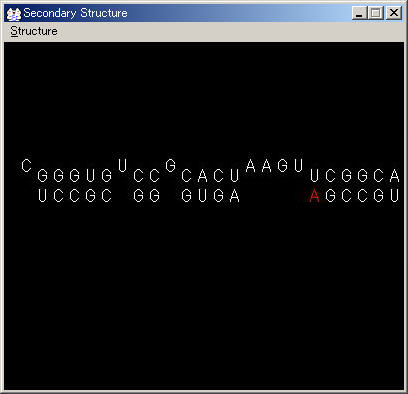
配列中で文字が赤くなっている位置の次に残基が追加・挿入されます.
二次構造の任意の個所をマウスの左ボタンでクリックし追加・挿入したい部位を切り換えます.
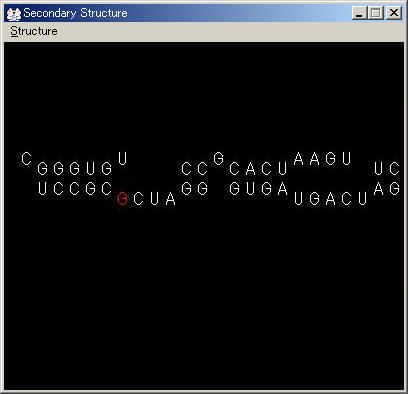
STEP 4: 分岐構造
二次構造が分岐している場合にはCOURSEを変更して進行方向を指定します.
基本的に進行方向の変更は直進か左折のみです.
また,タンパク質のモデリングには分岐がありません.


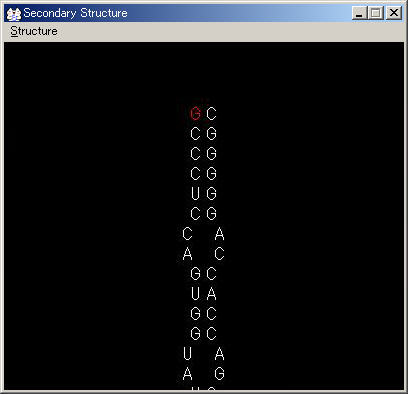
STEP 5: ループ作成
ループ部分は二次構造の末端の塩基対をクリックし,FORMをLOOPにすることで作成できます.
配列がループ状になっていれば問題ありません.
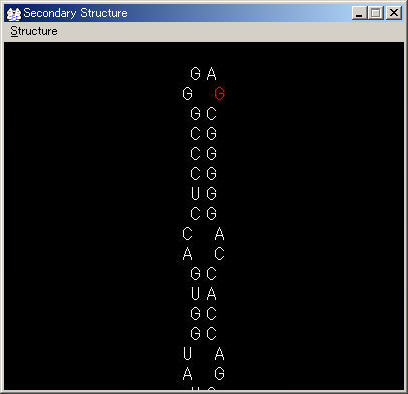
STEP 6: 完成
もし入力を間違えても大きな間違いでなければUNDOで一つ前の状態に戻ることができます.
また二次構造表示ウィンドウのStructureメニューのSaveで表示中の二次構造を保存できます.
拡張子は(.mss)です.
モデリング作業が長くかかりそうな場合には定期的に保存されることをお薦めします.
最後まで配列を入力していきます.
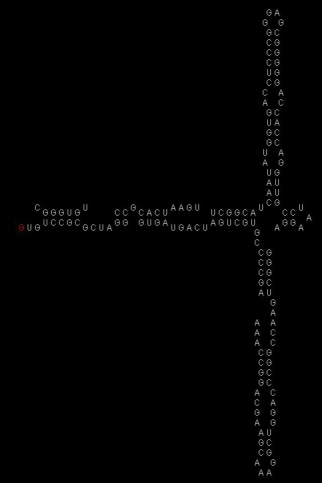
配列を入力し終えたらメニューウィンドウのEXECUTEを押します.
モデリングの計算が始まり,配列の長さによって数秒から2〜3分かかることがあります.
立体構造がメインウィンドウに表示されます.

STEP 7: タンパク質のモデリング
タンパク質のモデリングでは4種類のFORMが用意されています.
[A-HELIX]ではαヘリックスを形成し,[B-SHEET]ではβシートを形成します.
[RANDOM]を選択するとタンパク質の主鎖の角度がランダムに決定されます.
ModelingのExtractionメニュー
で作成したMEXファイルにタンパク質の情報が記述されていると,この[RANDOM]を指定した配列との情報比較が行われます.
[SPECIFIC]では主鎖の角度情報を任意に設定できます.
PHIはC,N,CA,Cの二面角,
PSIはN,CA,C,Nの二面角,
OMEGAはCA,C,N,CAの二面角を設定します.
角度は,-180 〜 180 度の範囲で指定します.